前言
上篇文章 PyQuery (一) 回顾。今天来介绍具体 PyQuery 的使用方法。
穷游网目标与分析
开始之前,按照之前的套路一步步来。
一、先确立目标。
我们要爬取的目标是:
- 日本的城市
- 去过的人数
- 城市的详情景点
二、看源码,分析元素节点。
F12 查看当前网页源代码:
https://place.qyer.com/japan/citylist-0-0-1/
选中下图区域,可以看到这是一个 ul 标签,class 为 plcCitylist 。
- ul:unordered list,“无序列表”的意思。
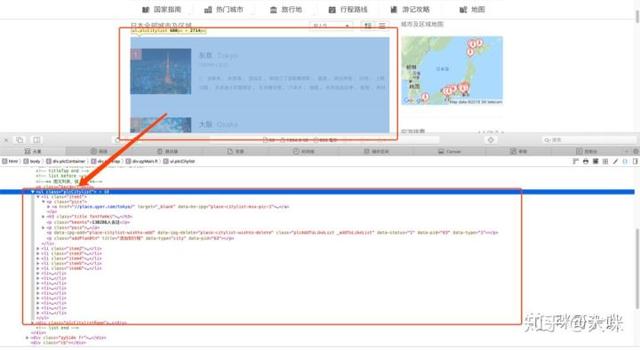
在这个无序标签里,有许多 li 标签,class 为 item+数字。
- li:list item,“列表项”的意思。
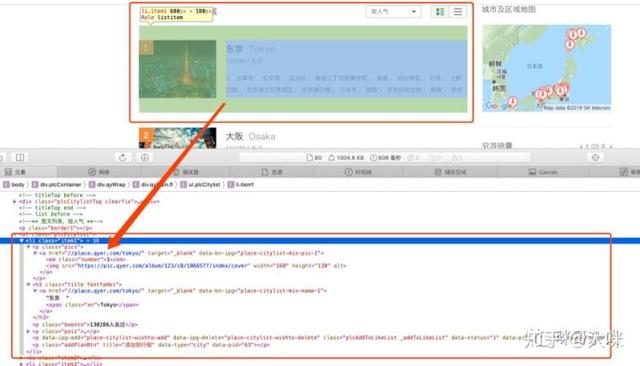
城市名字:包含在 a 标签中。
去过的人数:包含在 h3 标签中,且在 p 标签中,class 为 beenton 中。
详情景点:包含在 h3 标签中,且在 p 标签中,class 为 pois 中,且在 a 标签中。
- h3:给文本增加主标题的语义。(显示在页面上标题变粗)
- p:段落标签
以上分析完了,其实单纯分析节点很简单。重点在于代码如何使用。
PyQuery代码详讲
依然是分步骤来提取我们想要的。
回忆一下,用 PyQuery 请求到源代码,拿到实例对象。
from pyquery import PyQuery as pq
doc = pq(‘https://place.qyer.com/japan/citylist-0-0-1’)
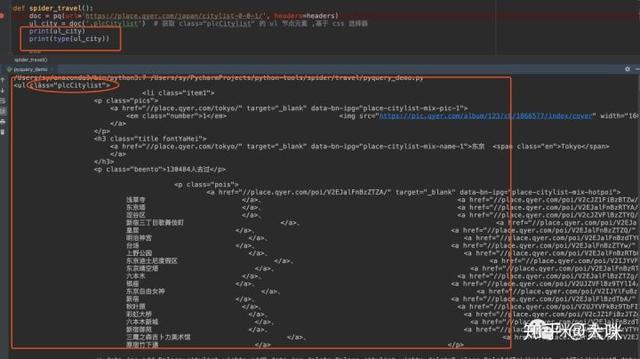
1. css选择器,提取外层 ul
ul_city = doc(‘.plcCitylist’)
基于 css 选择器,获取 class=”plcCitylist” 的 ul 节点元素。因为 class 值唯一,上面说过了。
在 JQuery 的语法中, . 代表着类选择器的写法,而 # 代表着 id 选择器的写法。所以直接用 .值 ,直接可以获取当前标签元素节点,如下:
当然,如果当标签不唯一时,你也可以这样操作,在.前面声明具体标签:
ul_city = doc(‘ul.plcCitylist’)
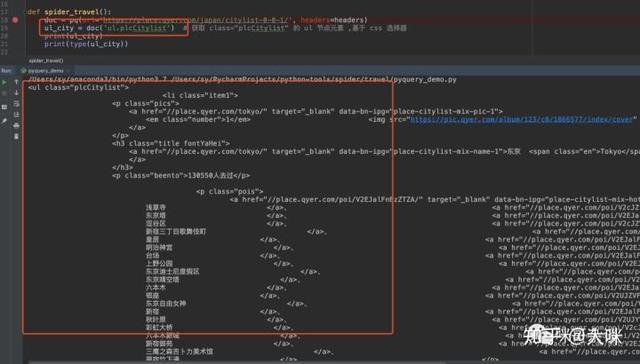
但需要注意的是,尽管我们 print 打印是你看到的文字,它们实际上并不是 str 类型的字符串,而是 PyQuery 这个类型。
3. 遍历单独的 li 元素节点
当我们获取 ul 下面的 li 元素节点时,匹配到的肯定是多个。此时想要逐个解析 li ,并且获取到 li 中的城市名称等抓取信息如何做呢?
for li in lis.items():
通过调用 PyQuery 对象的 items 方法,即可逐层遍历相同元素,就像我们的 list 一样。
4. 标签多个 class 确定唯一值的选择器写法
仔细看我们 li 节点中的 h3 标签,class 里面是有两个值的。
<h3 class = “title fontYaHei”>………….
通过这两个值的唯一性,我们可以直接定位到 h3 元素。
h3 = li(‘.title.fontYaHei’)
5. PyQuery 属性选择节点
如果你用不惯以上的所有获取节点元素的方法, PyQuery 还提供了一个便利的方法,即通过标签元素的属性进行定位元素。
a_city = h3(‘a’).attr(‘data-bn-ipg’, ‘place-citylist-mix-name-1’)
h3(‘a’) 获取的是 h3 标签里 a 标签的元素节点。 使用 .attr 时,后面两个参数说明 a 标签原本的属性由如下组成:
<a data-bn-ipg = “place-citylist-mix-name-1”>………….
attr 第一个参数是标签属性的名字,第二个参数则是属性具体的值。
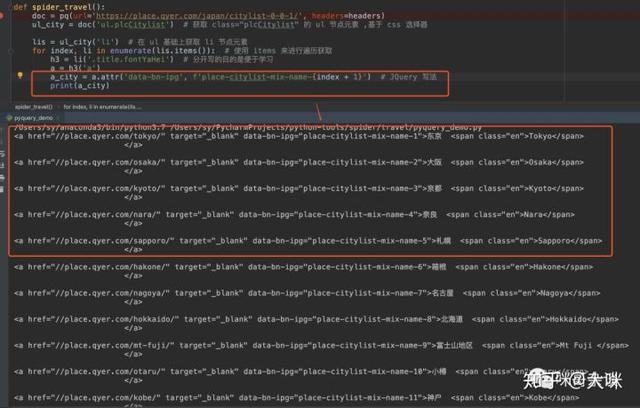
成果展示
最终的成果展示如下:

选成文本,完成即可,自己就换行显示了。