鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
Transformer自诞生以来,就在NLP领域刷新一个又一个纪录,称作当下最流行的深度学习框架亦不为过。
不过,拿下SOTA并不意味着十全十美。
比如,在长序列训练上,Transformer就存在计算量巨大、训练成本高的问题。
其对内存的要求从GB级别到TB级别不等。这意味着,模型只能处理简短的文本,生成简短的音乐。
此外,许多大型Transformer模型在经过模型并行训练之后,无法在单个GPU上进行微调。
现在,谷歌和UC伯克利推出了一个更高效的Transformer模型——Reformer。
在长度为L的序列上,将复杂度从 O(L2)降低到了O(L logL)。
并且,模型训练后,可以仅使用16GB内存的单个GPU运行。

其中,Q矩阵由一组query的注意力函数组成,key打包为矩阵K,value打包为矩阵V,dk为query和key的维度。
在softmax(QKT)中,softmax受最大元素控制,因此对于每个query(qi),只需要关注K中最接近qi的key。这样效率会高得多。
那么如何在key中寻找最近邻居呢?
局部敏感哈希就可以解决在高维空间中快速找到最近邻居的问题。
局部敏感哈希指的是,如果邻近的向量很可能获得相同的哈希值,而远距离的向量没可能,则给每个向量x分配哈希值h(x)。
在这项研究中,实际上仅需要求邻近向量以高概率获得相同的哈希,并且哈希桶的大小高概率相似。
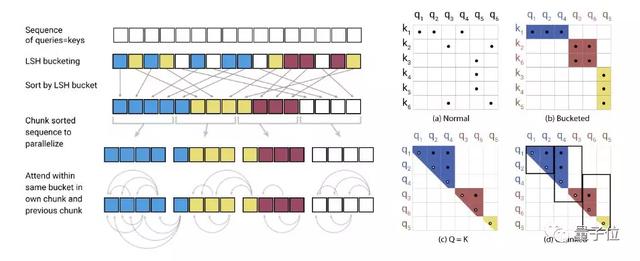
于是,研究人员引入了可逆层和分段处理,来进一步降低成本。

可逆Transformer无需在每个层中存储activations。
这样一来,整个网络中activations占用的内存就与层数无关了。
实验结果
研究人员在enwik8和imagenet64数据集上对20层的Reformer模型进行了训练。
实验表明,Reformer能达到与Transformer相同的性能,并且内存效率更高,模型在长序列任务上训练更快。