集合是Java开发日常开发中经常会使用到的,而作为一种典型的K-V结构的数据结构,HashMap对于Java开发者一定不陌生。
在日常开发中,我们经常会像如下方式以下创建一个HashMap:
Map<String, String> map = new HashMap<String, String>();
但是,大家有没有想过,上面的代码中,我们并没有给HashMap指定容量,那么,这时候一个新创建的HashMap的默认容量是多少呢?为什么呢?
本文就来分析下这个问题。
什么是容量
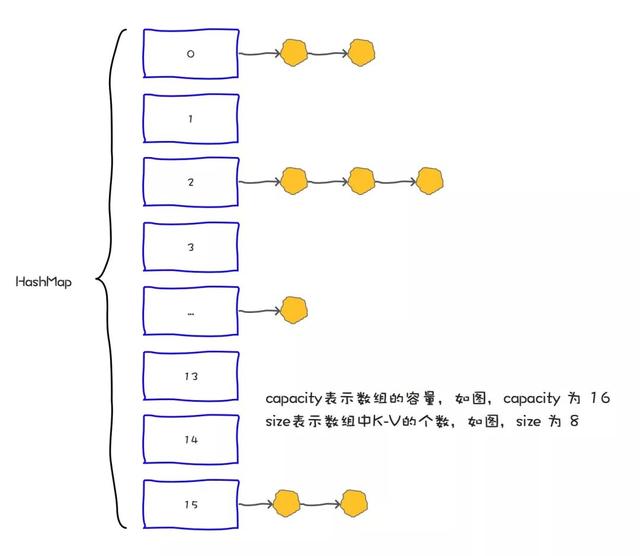
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。HashMap就是将数组和链表组合在一起,发挥了两者的优势,我们可以将其理解为链表的数组。
在HashMap中,有两个比较容易混淆的关键字段:size和capacity ,这其中capacity就是Map的容量,而size我们称之为Map中的元素个数。
简单打个比方你就更容易理解了:HashMap就是一个“桶”,那么容量(capacity)就是这个桶当前最多可以装多少元素,而元素个数(size)表示这个桶已经装了多少元素。
我们知道,hash方法的功能是根据Key来定位这个K-V在链表数组中的位置的。也就是hash方法的输入应该是个Object类型的Key,输出应该是个int类型的数组下标。如果让你设计这个方法,你会怎么做?
其实简单,我们只要调用Object对象的hashCode()方法,该方法会返回一个整数,然后用这个数对HashMap的容量进行取模就行了。
如果真的是这么简单的话,那HashMap的容量设置就会简单很多了,但是考虑到效率等问题,HashMap的hash方法实现还是有一定的复杂的。
hash的实现
接下来就介绍下HashMap中hash方法的实现原理。(下面部分内容参考自我的文章:全网把Map中的hash()分析的最透彻的文章,别无二家。PS:网上的关于HashMap的hash方法的分析的文章,很多都是在我这篇文章的基础上”衍生”过来的。)
具体实现上,由两个方法int hash(Object k)和int indexFor(int h, int length)来实现。
hash :该方法主要是将Object转换成一个整型。
indexFor :该方法主要是将hash生成的整型转换成链表数组中的下标。
为了聚焦本文的重点,我们只来看一下indexFor方法。我们先来看下Java 7(Java8中虽然没有这样一个单独的方法,但是查询下标的算法也是和Java 7一样的)中该实现细节:
static int indexFor(int h, int length) {
return h & (length-1);
}
indexFor方法其实主要是将hashcode换成链表数组中的下标。其中的两个参数h表示元素的hashcode值,length表示HashMap的容量。那么return h & (length-1) 是什么意思呢?
其实,他就是取模。Java之所有使用位运算(&)来代替取模运算(%),最主要的考虑就是效率。
位运算(&)效率要比代替取模运算(%)高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。
那么,为什么可以使用位运算(&)来实现取模运算(%)呢?这实现的原理如下:
X % 2^n = X & (2^n – 1)
假设n为3,则2^3 = 8,表示成2进制就是1000。2^3 -1 = 7 ,即0111。
此时X & (2^3 – 1) 就相当于取X的2进制的最后三位数。
从2进制角度来看,X / 8相当于 X >> 3,即把X右移3位,此时得到了X / 8的商,而被移掉的部分(后三位),则是X % 8,也就是余数。
上面的解释不知道你有没有看懂,没看懂的话其实也没关系,你只需要记住这个技巧就可以了。或者你可以找几个例子试一下。
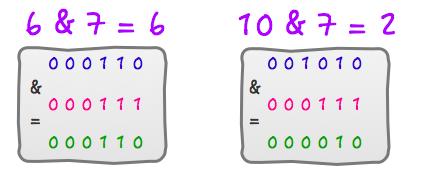
6 % 8 = 6 ,6 & 7 = 6
10 & 8 = 2 ,10 & 7 = 2
运算过程如下如:
请关注上面的几个例子中,蓝色字体部分的变化情况,或许你会发现些规律。5->8、9->16、19->32、37->64都是主要经过了两个阶段。
Step 1,5->7
Step 2,7->8
Step 1,9->15
Step 2,15->16
Step 1,19->31
Step 2,31->32
对应到以上代码中,Step1:
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
对应到以上代码中,Step2:
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
Step 2 比较简单,就是做一下极限值的判断,然后把Step 1得到的数值+1。
Step 1 怎么理解呢?其实是对一个二进制数依次向右移位,然后与原值取或。其目的对于一个数字的二进制,从第一个不为0的位开始,把后面的所有位都设置成1。
随便拿一个二进制数,套一遍上面的公式就发现其目的了:
1100 1100 1100 >>>1 = 0110 0110 0110
1100 1100 1100 | 0110 0110 0110 = 1110 1110 11101110 1110 1110 >>>2 = 0011 1011 1011
1110 1110 1110 | 0011 1011 1011 = 1111 1111 1111
1111 1111 1111 >>>4 = 1111 1111 1111
1111 1111 1111 | 1111 1111 1111 = 1111 1111 1111
通过几次无符号右移和按位或运算,我们把1100 1100 1100转换成了1111 1111 1111 ,再把1111 1111 1111加1,就得到了1 0000 0000 0000,这就是大于1100 1100 1100的第一个2的幂。
好了,我们现在解释清楚了Step 1和Step 2的代码。就是可以把一个数转化成第一个比他自身大的2的幂。
但是还有一种特殊情况套用以上公式不行,这些数字就是2的幂自身。如果数字4套用公式的话。得到的会是 8,不过其实这个问题也被解决了,具体验证办法及JDK的解决方案见全网把Map中的hash()分析的最透彻的文章,别无二家。这里就不再展开了。
总之,HashMap根据用户传入的初始化容量,利用无符号右移和按位或运算等方式计算出第一个大于该数的2的幂。
扩容
除了初始化的时候会指定HashMap的容量,在进行扩容的时候,其容量也可能会改变。
HashMap有扩容机制,就是当达到扩容条件时会进行扩容。HashMap的扩容条件就是当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容。
在HashMap中,threshold = loadFactor * capacity。
loadFactor是装载因子,表示HashMap满的程度,默认值为0.75f,设置成0.75有一个好处,那就是0.75正好是3/4,而capacity又是2的幂。所以,两个数的乘积都是整数。
对于一个默认的HashMap来说,默认情况下,当其size大于12(16*0.75)时就会触发扩容。
下面是HashMap中的扩容方法(resize)中的一段:
if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
从上面代码可以看出,扩容后的table大小变为原来的两倍,这一步执行之后,就会进行扩容后table的调整,这部分非本文重点,省略。
可见,当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容,扩容成原容量的2倍,即从16扩容到32、64、128 …
所以,通过保证初始化容量均为2的幂,并且扩容时也是扩容到之前容量的2倍,所以,保证了HashMap的容量永远都是2的幂。
总结
HashMap作为一种数据结构,元素在put的过程中需要进行hash运算,目的是计算出该元素存放在hashMap中的具体位置。
hash运算的过程其实就是对目标元素的Key进行hashcode,再对Map的容量进行取模,而JDK 的工程师为了提升取模的效率,使用位运算代替了取模运算,这就要求Map的容量一定得是2的幂。
而作为默认容量,太大和太小都不合适,所以16就作为一个比较合适的经验值被采用了。
为了保证任何情况下Map的容量都是2的幂,HashMap在两个地方都做了限制。
首先是,如果用户制定了初始容量,那么HashMap会计算出比该数大的第一个2的幂作为初始容量。
另外,在扩容的时候,也是进行成倍的扩容,即4变成8,8变成16。
本文,通过分析为什么HashMap的默认容量是16,我们深入HashMap的原理,分析了下背后的原理,从代码中我们可以发现,JDK 的工程师把各种位运算运用到了极致,想尽各种办法优化效率。值得我们学习!
最后,留一个思考题,既然HashMap并不会直接接收用户传入的初始容量,那么为什么《阿里巴巴Java开发手册》还是建议开发者在创建HashMap的时候制定一个初始容量呢?这个容量设置成多少合适呢?为什么?
关于作者:Hollis,一个对Coding有着独特追求的人,现任阿里巴巴技术专家,个人技术博主,技术文章全网阅读量数千万,《程序员的三门课》联合作者。
分享自:https://maimai.cn/article/detail?fid=1386914852&efid=I9gMBxWE2I5ota4RpogAQw&use_rn=1