作者 | Tirthajyoti Sarkar
译者 | 清儿爸
编辑 | 夕颜
来源 | AI科技大本营(ID: rgznai100)
【导读】Pandas 是 Python 生态系统中的一个了不起的库,用于数据分析和机器学习。它在 Excel/CSV 文件和 SQL 表所在的数据世界与 Scikit-learn 或 TensorFlow 施展魔力的建模世界之间架起了完美的桥梁。
数据科学流通常是一系列的步骤:数据集必须经过清理、缩放和验证,之后才能被强大的机器学习算法使用。
当然,这些任务可以通过 Pandas 等包提供的许多单步函数或方法来完成,但更为优雅的方式是使用管道。在几乎所有的情况下,通过自动执行重复性任务,管道可以减少出错的机会,并能够节省时间。
在数据科学领域中,具有管道特性的软件包有 R 语言的 dplyr 和 Python 生态系统中的 Scikit-learn。
要了解它们在机器学习工作流中的应用,你可以读这篇很棒的文章:
https://www.kdnuggets.com/2017/12/managing-machine-learning-workflows-scikit-learn-pipelines-part-1.html
Pandas 还提供了 `.pipe` 方法,可用于类似的用户定义函数。但是,在本文中,我们将讨论的是非常棒的小库,叫 pdpipe,它专门解决了 Pandas DataFrame 的管道问题。
使用 Pandas 的流水线
Jupyter Notebook 的示例可以在我的 Github 仓库中找到:
https://github.com/tirthajyoti/Machine-Learning-with-Python/blob/master/Pandas%20and%20Numpy/pdpipe-example.ipynb。
让我们看看如果使用这个库来构建有用的管道。
数据集
为了演示,我将使用美国房价的数据集,可从 Kaggle 下载:
https://www.kaggle.com/vedavyasv/usa-housing
我们可以在 Pandas 中加载数据集,并显示其汇总的统计信息,如下所示:
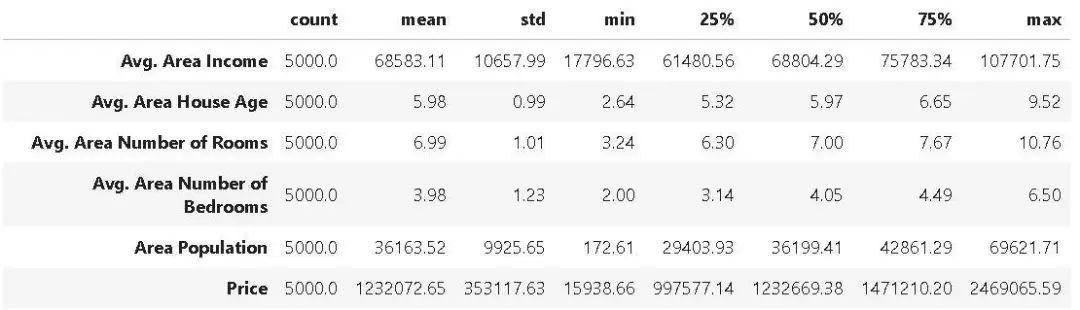
经过此步骤之后,数据集如下所示:
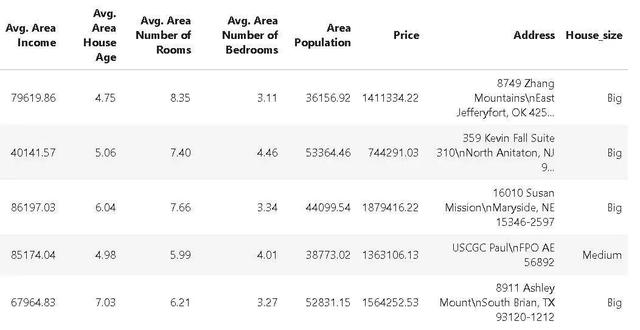
只需添加管道链级
只有当我们能够进行多个阶段时,管道才是有用和实用的。在 pdpipe 中有多种方法可以实现这一点。但是,最简单、最直观的方法是使用 + 运算符。这就像手工连接管道一样!
比方说,除了删除 `age` 列之外,我们还希望对 `House size` 的列进行独热编码,以便可以轻松地在数据集上运行分类或回归算法。
pipeline = pdp.ColDrop(‘Avg. Area House Age’)pipeline+= pdp.OneHotEncode(‘House_size’)df3 = pipeline(df)
因此,我们首先使用 `ColDrop` 方法创建了一个管道对象来删除 `Avg. Area House Age` 列。此后,我们只需使用常用的 Python 的 `+=` 语法将 `OneHotEncode` 方法添加到这个管道对象中即可。
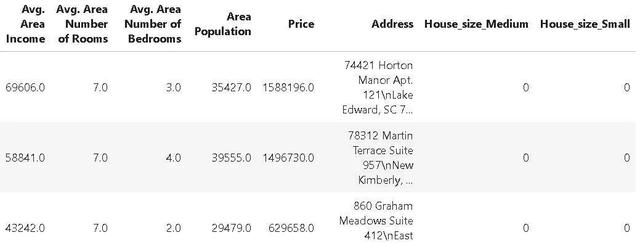
生成的 DataFrame 如下所示。请注意,附加的指示列 `House_size_Medium` 和 `House_size_Small` 是由独热编码创建的。
第二种方法是,在 `Price_tag` 中查找字符串 `drop`,并删除那些匹配的行。最后,第三个方法就是删除 `Price_tag` 标签列,清理 DataFrame。毕竟,这个 `Price_tag`列只是临时需要的,用于标记特定的行,在达到目的后就应该将其删除。
所有这些都是通过简单地链接同一管道上的各个阶段来完成的!
现在,我们可以回顾一下,看看我们的管道从一开始对 DataFrame 都做了什么工作:
- 删除特定的列。
- 独热编码,用于建模的分类数据列。
- 根据用户定义函数对数据进行标记。
- 根据标记删除行。
- 删除临时标记列。
所有这些,使用的是以下五行代码:
pipeline = pdp.ColDrop(‘Avg. Area House Age’)
pipeline+= pdp.OneHotEncode(‘House_size’)
pipeline+=pdp.ApplyByCols(‘Price’,price_tag,’Price_tag’,drop=False)
pipeline+=pdp.ValDrop([‘drop’],’Price_tag’)
pipeline+= pdp.ColDrop(‘Price_tag’)
df5 = pipeline(df)
最近版本更新:直接删除行!
我与包作者 Shay Palachy 进行了精彩的讨论,他告诉我,该包的最新版本可以用 lambda 函数,仅用一行代码即可完成行的删除(满足给定的条件),如下所示:
pdp.RowDrop({‘Price’: lambda x: x <= 250000})
Scikit-learn 与 NLTK
还有许多更有用、更直观的 DataFrame 操作方法可用于 DataFrame 操作。但是,我们只是想说明,即使是 Scikit-learn 和 NLTK 包中的一些操作,也包含在 pdpipe 中,用于创建非常出色的管道。
Scikit-learn 的缩放估算器
建立机器学习模型最常见的任务之一是数据的缩放。Scikit-learn 提供了集中不同类型的缩放,例如,最小最大缩放,或者基于标准化的缩放(其中,数据集的平均值被减去,然后除以标准差)。
我们可以在管道中直接链接这些缩放操作。下面的代码段演示了这种用法:
pipeline_scale = pdp.Scale(‘StandardScaler’,exclude_columns=[‘House_size_Medium’,’House_size_Small’])
df6 = pipeline_scale(df5)
本文中,我们应用了 Scikit-learn 包中的 `StandardScaler` 估算器来转换数据以进行聚类或神经网络拟合。我们可以选择性地排除那些无需缩放的列,就像我们在本文中对指示列 `House_size_Medium` 和 `House_size_Small` 所做的那样。
瞧!我们得到了缩放后的 DataFrame:

总结
如果我们对本文这个演示中显示的所有操作进行总结,则如下所示: