允中 发自 凹非寺
量子位 编辑 | 公众号 QbitAI
你走进澡堂,雾气弥漫。眼睛看到的人影模模糊糊。既看不清楚细节,也不知道是谁,只能看到大概轮廓。
你觉得手足无措,一分钟都不想待在那里。
你看到的情景,就是听障人士在真实世界里听到的情况。雾气相当于他们听到的嘈杂的声音。所有声音的细节统统丢失,听到的人声和音乐声,都淹没在一片非常浓厚嘈杂的噪音里。
对我们健全人来说,一直在雾气弥漫的场景里看东西,可以想象多么痛苦。对于听障人士而言,他们一辈子,7×24小时,都被困在了这样的环境里。
“如果能帮助他们,让他们听得见、听得清、听得真,听到我们健全人能听见的声音,那真是一件非常有意义的事情。”腾讯多媒体实验室高级总监商世东表示。
刚过去的9月27日,国际聋人日当天,腾讯多媒体实验室联合腾讯公益慈善基金会、深圳市信息无障碍研究会等机构召开发布会,宣布发起“天籁行动”——面向公益开发者、设备厂商、相关机构开放腾讯天籁AI音频技术,应用于听障人群无障碍建设等相关社会责任领域。
天籁行动,是腾讯“科技向善”的一次最新实践。从2019年11月11日开始,腾讯将“科技向善”写进公司最新的使命与愿景之中。
科技与人类的关系,在近年越发受到关注和讨论。事实上,不只腾讯,诸多科技公司都开始重视和强调用好科技,以科技为善:腾讯强调“科技向善”,华为强调“科技至善”。
如何让“科技向善”不是一句简单的口号,更要真正成为一个持续落地的使命。其背后的驱动机制,来自科技公司的技术外溢与产品力,带来持续不断的技术进步、产品落地和公益体系化建设。
腾讯天籁行动,正是这一科技向善机制的典型体现。腾讯分三步,实现了用AI帮助听障人士的科技实践:释放20余年音频技术积累,以产品力将技术落地于听障人群,为不同定制化场景研发针对性降噪解决方案。最终实现将人工耳蜗语音清晰度和识别度提升40%,极大改善听障人士的听觉体验,让他们“听得见”,更“听得清”。
1、从技术,到场景
优秀的技术研究团队,都有一个共同的特质:喜欢迎接未知的挑战,不断突破;越是遇到棘手的挑战,就会越兴奋。商世东和他所在的腾讯多媒体实验室,就是这样一支团队。
腾讯多媒体实验室,是腾讯公司前沿技术实验室之一,专注音视频通信技术的前瞻性研究,最擅长语音增强和降噪技术。针对语音在嘈杂环境中的情况,他们把经典信号处理和机器学习技术融合在一起,加上声学场景分析技术,打造了一套降噪解决方案。他们把降噪技术应用在包括腾讯会议等多个产品里,经过各种场景,各种设备,各样用户的体验和打磨,成功实现了国际领先的核心语音增强和降噪技术指标。
作为一个专注声音的研究团队,商世东和同事们在公司的一些无障碍项目交流当中,不止一次接触到听障人群。他们对声音的渴望,以及很多家庭为了孩子获得听的权利,付出了很多常人无法想象的努力,他们的坚持和努力,让人触动。
“一开始,这个技术是用在健全人的通信当中。但其实听障人员更需要语音增强和降噪技术,是用来解决他们听得见、听得懂的问题。”商世东说,”降噪技术对健全人是锦上添花,对听障人士是雪中送炭。”
世界卫生组织(WHO)数据显示,全球有约11亿年轻人(12-35岁之间)面临听力损失的风险,约4.66亿人患有残疾性听力损失。据第二次全国残疾人抽样调查结果显示,我国有听力残疾患者2780万人。而这2780万听障人士,通过科技填补自身缺陷的,不到5%。
商世东和腾讯多媒体实验室的同事们决定,将降噪技术贡献出来,提供给人工耳蜗厂商,让他们可以把采集到的声音信号进行降噪,帮助听障人士摆脱噪音烦恼,听到的干净得多、安静得多的声音世界。
但当他们试图把技术运用到人工耳蜗场景时,商世东和团队发现,他们遇到了前所未有的挑战:技术不是拿过来就可以用的,他们需要真正了解,对人工耳蜗用户来说,他们感到最痛的问题是什么。
“技术应用必须要场景驱动。我们需要了解,什么样的场景,人工耳蜗用户他们有最迫切的需要。” 商世东说。
“我们应该为他们做点什么?我们能为他们做点什么?”这是商世东和团队讨论最多的问题。
AI降噪技术需要在降噪和听觉感受之间取得平衡——人们可以听到一些场景声音,但不能太吵;不是一点噪声都没有,但要能把噪声能量控制在可接受的范围之内。
商世东和团队针对人工耳蜗的用户痛点,展开了深入调研。他们发现,对于人工耳蜗用户来说,有四类典型场景:第一类是音乐场景,他们想听音乐或看电视。第二类是干净的纯净语音场景,例如在家里只有跟家人的对话,没有太多嘈杂的声音。第三类是纯噪声的场景,比如戴着人工耳蜗的孩子想出去走一走,马路上有噪声,如果除了噪音什么都听不见就比较危险。第四类是带噪的语音场景,比如他们走在嘈杂的街道上,还能听得清,知道谁在跟他们讲话。
第三和第四类场景,是人工耳蜗用户们最痛的地方。没有AI降噪技术之前,技术很多时候顾此失彼,把所有的声音都放大了。他们在家里跟家人对话能听到,但是出去之后,有一些不想听到的声音就没办法屏蔽,特别吵。这时候又不能关掉人工耳蜗,否则什么都听不见了。
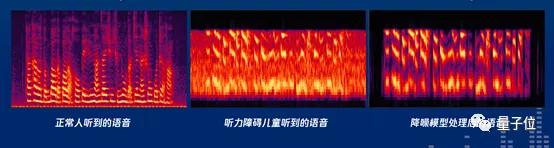
△ 听障人士和健全人听到的声音波形对比
这个过程中最难的地方在于,如何判断哪些是噪音,哪些是有用的背景音?你去听一场交响乐,主旋律之外的鼓点、人们鼓掌的声音,都是突发的声音,机器很难判断是噪音,还是音乐。技术很容易把噪声识别成音乐。这给他们的研发进程带来了很大困扰。
“机器对连续的音乐很容易判断出来,但打击乐混在里面,机器很难讲它是噪声还是什么。就像打个喷嚏,我们语音特征也会显示是突发的噪声。噪声需要消除,但音乐不能消除,需要把音乐尽可能地保留住。” 商世东说。
为了解决这个困难,腾讯多媒体实验室针对性开发了针对人工耳蜗用户的多场景识别技术。通过人工智能深度学习做场景分类,用户常见的几种场景都能准确识别。比如听障儿童打电话的场景,声音里从电话里出来,跟声音从日常自然界出来又是不一样的,这个技术能把电话场景进一步识别出来。
针对人工耳蜗用户常见的4类声学场景,腾讯多媒体实验室在业界首次采用了基于深度学习的残差网络结构,在多尺度和多级别的网络架构环境之下,对收集到的再造语音进一步的处理。多尺度的架构可以有效的区分上面显示的4位的声学场景,而多级别的网络架构可以进一步区分易于混淆的代造和代造语言的场景。
经过这样的处理,降噪技术总体上取得了96.2%的场景识别准确率。这个结果超过的人工标注的结果,为下一步做进一步增强和语音处理奠定了扎实的基础。
2、是技术,更是艺术
人工耳蜗虽然小,但是面临的挑战巨大。将降噪技术与听障场景相结合,比起纯技术研究的直线突破,更像一场“在针尖上起舞”的艺术。
商世东和团队必须要解决一个两难的应用问题:如何在极其有限的算力条件约束下,处理高复杂度的现实噪声?
使用人工耳蜗的听障用户,听到的声音跟健全人听到的声音有很大区别。一个关键原因是,他们本身听觉细胞比健全人要少得多。
15岁的晓婷,是广东佛山的高一学生,也是这次天籁行动中的听障用户之一。晓婷在两年前,装上人工耳蜗,第一次听到了这个世界的声音。可她却无法认出妈妈的声音。在晓婷听来,男人的声音是低沉的,女人的声音是尖细的,但她无法分辨每个人的声音有什么不同。
健全人有15000个听觉细胞,能够让你听到非常精细的,带有非常丰富音频细节的声音。而听障人群的听觉细胞显著低于健全人,可能只有几千个、几百个,甚至于最差的只有几十个,对声音的解析力不够。所以他们听到的声音非常模糊,听不清、听不见。
助听器和人工耳蜗,最主要的功能是把音量放大。但是在把音量放大的同时,把很多很多的环境噪声也放大了。
人耳对噪声非常敏感,不同频段的敏感程度也不一样。当把音量放大以后,健全人觉得并不是太吵的环境噪声,比方说空调声、风扇声,或者是马路上的声音,听障人士听起来会觉得嘈杂得不得了。
经典的声音处理,很难提升人工耳蜗对听障人士带来的听觉体验。经典声音信号处理时,如果要达到很好的降噪效果,需要很强的计算能力。人工耳蜗是戴在耳朵上的,既要轻,又没有电源(现在都是电池供电),所以运算能力非常有限。
当我们的电脑和手机达到主频是GHz多核架构的时候,人工耳蜗由于尺寸限制,往往只能有几十MHz的处理能力。在这样的处理能力条件下,需要高复杂度的噪声处理成为了业界的难点,为了克服这个难点,很多公司在进行这方面的研究,但一直没有突破。

△ 人工耳蜗原理图
今年年初,商世东和团队找到了国内最大人工耳蜗厂商之一诺尔康公司。他们一起反复探讨,在现有的软硬件资源局限条件之下,如何帮助人工耳蜗的佩戴者有更好的体验。
经过反复讨论和技术验证,他们最终确定了手机伴侣APP加人工耳蜗的联合优化方案。在手机上,通过手机强大的语音处理和采集能力,对采集到的语音进行场景识别和场景有针对性的降噪和增量处理。针对处理过的语音,通过有线或者无线的方式发送到人工耳蜗,人工耳蜗可以进一步刺激相应的听觉神经,有效的改善听觉体验的效果。
针对噪声消除,腾讯多媒体实验室有效融合了经典数字信号处理和深度学习技术。经典数字信号处理在解决平稳噪声上有独特的优势,计算复杂较低,但处理日常生活中的非频率噪声往往力不从心。而深度学习技术有非常优秀的特征建模能力,可以针对日常生活中的各种噪声进行准确的建模,从而有效预除生活中突发的噪声,但深度学习的缺点在于运算量复杂。为了进一步降低运算复杂度,他们采用了多种辅助训练方法,并把训练后的模型进一步量化处理,把运算复杂度有效的降低到1兆尺寸以下,解决了低功耗的手机终端上运行降噪处理的难题。
考虑到手机上多麦克风的情况,腾讯多媒体实验室进一步采用了以前在雷达以及智能天线领域使用的波束形成技术,进一步辅助降噪和语音的正常的处理,有效对特定方向的语音进行针对性加强,同时滤除非特定方向的干扰人声以及环境噪声。
通过使用多尺度、多级别的人工智能机器学习模型,商世东和团队为不同定制化场景研发了更有针对性的、更优的降噪解决方案,针对场景的识别率从60%提升到平均96%。经过多种技术的整合和处理,有效提升了听障人士在各种沟通场景之下的效率,帮助消除他们不想听到的声音。
试戴新一代人工耳蜗第一天,晓婷和妈妈一起去公园,突然听见了从来没有听过的声音。妈妈告诉她,这是鸟叫。她说:“妈妈,是两只鸟的声音。”妈妈惊讶了。她从来没有想到,晓婷不仅能够听清鸟叫,还能辨认出是两只鸟的叫声。

△ 腾讯多媒体实验室发布天籁行动,用AI技术帮助听障人士
3、腾讯的“技术外溢”与产品力
值得注意的是,天籁行动并非腾讯偶然一次心血来潮的公益实践。它是腾讯基于“科技向善”的价值观,进行体系化、持续性建设的公益产品落地之一。其背后的驱动机制,正是腾讯技术积累的“技术外溢”,以及将技术快速场景化落地的强大产品力。
“天籁行动”之所以能达到显著的语音增强和降噪效果,既源自于腾讯多媒体实验室多年的技术积累,尤其是在多媒体方向上的投入,也得益于腾讯内部众多产品的丰富场景应用、快速迭代创新。
腾讯多媒体实验室过往20年开发的音频技术,用在了腾讯QQ,腾讯课堂、腾讯语音等多个产品上,服务于全球最大的体量客户。
最近的一个例子是腾讯会议的实践。作为一款上市不到一年的产品,腾讯会议的用户数已经突破了1亿。其快速增长背后,是新一代实时音频技术加持——为腾讯用户在使用过程中提供高清、流畅、沉浸的音频通讯体验,解决在音视频场景里所碰到的挑战。这个技术就是应用于人工耳蜗的腾讯天籁。
不同技术互相取长补短,才能有更好的体验。为此,腾讯多媒体实验室组建了一支多元化的技术团队。商世东20多年一直在研究音频技术方向,团队里成员的背景也相当丰富:技术领域有偏重于声学的,有偏重于算法的,有偏重于机器学习的,有偏重经典信号处理的。专业背景既有中国顶尖高校,如中科大、北大等毕业的博士生加入,也招募了很多国际知名的人才加盟,包括来自新加坡国立大学、澳大利亚西澳大学,还有在德国工作多年的经典数字信号处理方面的专业人才……团队成员相互合作,技术融合创新,一块打磨音频体验。
同时,腾讯发挥自身的产品力优势,将前沿技术应用到“无障碍”、AI寻人等多项公益产品中,为信息无障碍贡献力量,持续为社会创造价值。
从2009年开始,腾讯的QQ、微信等产品,先后针对视障等用户进行了体验优化,开发了“无障碍”版本,让他们通过“听”也能使用,这些应用也成为他们离不开的生活伴侣。
2018年,QQ空间启动了“无障碍AI技术”开放项目,将OCR文字识别、语音合成、图片转语音等无障碍AI技术,通过小程序开放,企业、开发者可以免费接入。
2019年,优图实验室利用深度学习技术,突破“跨年龄人脸识别”技术,助力警方寻回多名被拐十年的儿童,帮助更多的家庭得以团聚。

△ 腾讯优图实验室利用人工智能(AI)深度学习技术,突破“跨年龄人脸识别”
今年,腾讯多媒体实验室将“新一代实时音频技术”——腾讯天籁,应用在人工耳蜗上。天籁行动不算惊天动地,但解决的问题存在很大技术挑战,过去不少尝试都没有成功。腾讯为什么能做到?因为腾讯具备了三点关键——腾讯20余年在音视频技术领域的积累,擅于将技术场景化落地的产品力,“科技向善”的情怀。
而这三点,也正保证了腾讯未来能持续实践“科技向善”价值观:坚持从用户价值出发,通过科技应用、场景创新,不断解决社会难题。
“我们要做到‘AI向善’,就要努力让人工智能实现‘可知、可控、可用、可靠’。这是全世界共同面对的课题。”腾讯公司董事会主席兼CEO马化腾表示,“腾讯把‘科技向善’纳入公司的使命和愿景,我们每天都在研究和应用新科技,归根到底要为每一位用户负责。”
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态